
Business Rule: File Name Parsing to Fieldsets
To categorize our content we can select to update product, event or corporate information. Lets focus on managing product information in Picturepark. Some content is about products. Some content is only about the product line, the industry, or the end-use sector. All files contain either the product name or just the industry or the end-use-sector.
Data Model
The layer prioritizes the product name - as this is the main type of content. Still, other product details are available as part of a fieldset.
LAYER "Product"
Tagbox "Product name"
Single Fieldset "Product details"
Tagbox "Product Line"
Tagbox "Industry"
Tagbox "End-use sector"
Tagbox "Various product tags"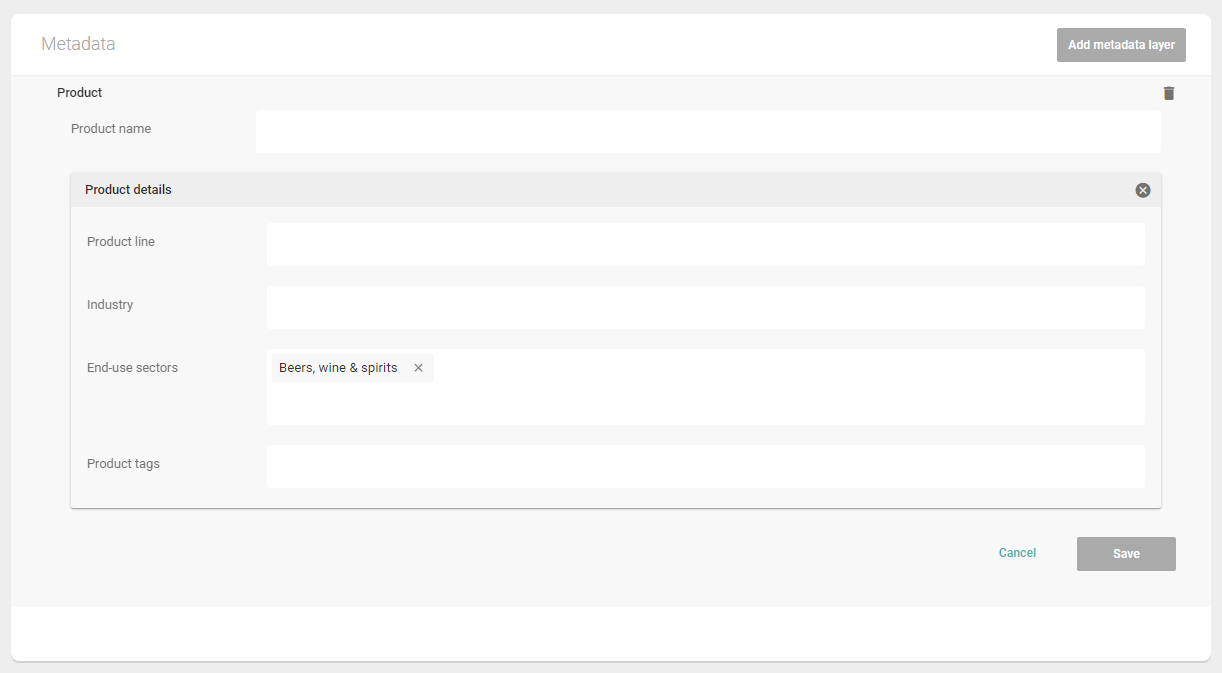
Business Rule JSON
Trigger
On creation of new Content Items.
"triggerPoint": {
"executionScope": "MainDoc",
"documentType": "Content",
"action": "Create"
},Condition
Check for images and extract information from the filename using regex.
Regex in use: https://regexr.com/5f202
- Optimization: use split (_), join (“ “), and ngram (size 1 - max words (4)) instead of regex for this kind of filenames.
"conditions": [
{
"kind": "ContentSchemaCondition",
"schemaId": "ImageMetadata",
"traceRefId": null
},
{
"kind": "MatchRegexCondition",
"fieldPath": "imageMetadata.fileName",
"regex": "(?:csm[ _])?(?:bobst[ _])?(?<product>\\w+)",
"storeIn": "parsed_eus",
"traceRefId": null
}
],Transformation
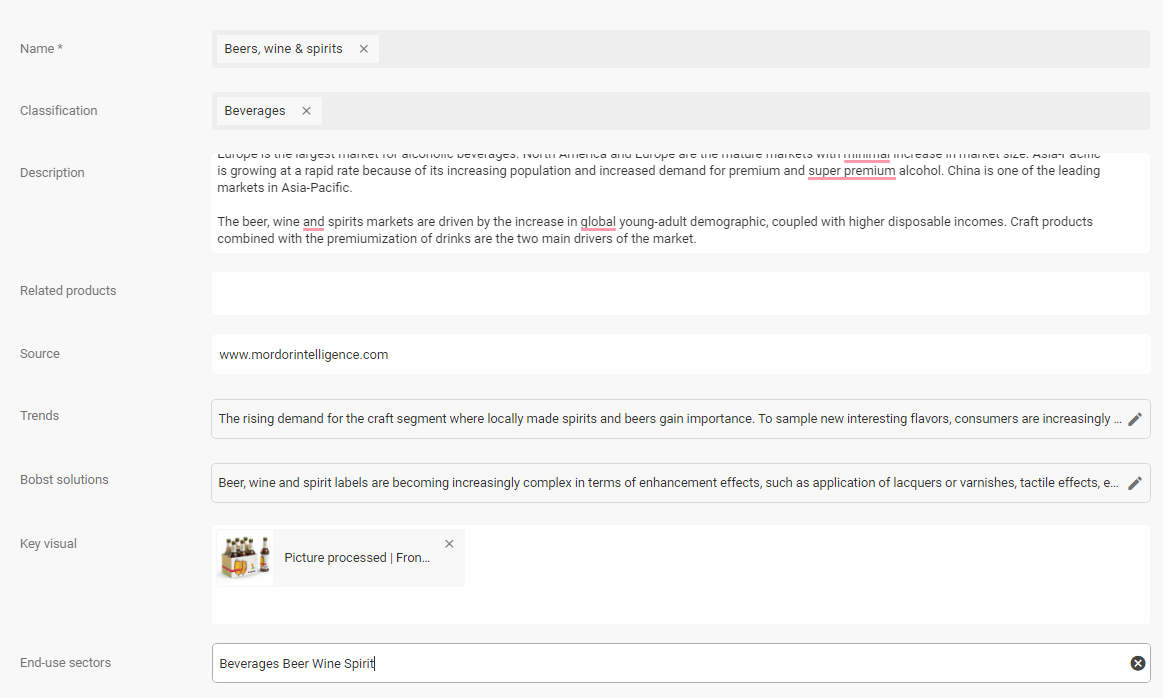
Lookup the product value from the filename regex, split the values separated by underline into single words, then join them with space. Then lookup the new value in the product cache.
The tagbox value “Beverages Beer Wine Spirit” must match the lookup. It must be an exact match.
Beverages Beer Wine Spirit = Beverages Beer Wine Spirit
Beverages Beer Wine Spirit != Beverages, Beer & Wine & Spirit
As a workaround, I use a non-indexed, non-searchable text field that holds the exact matching value.
Action
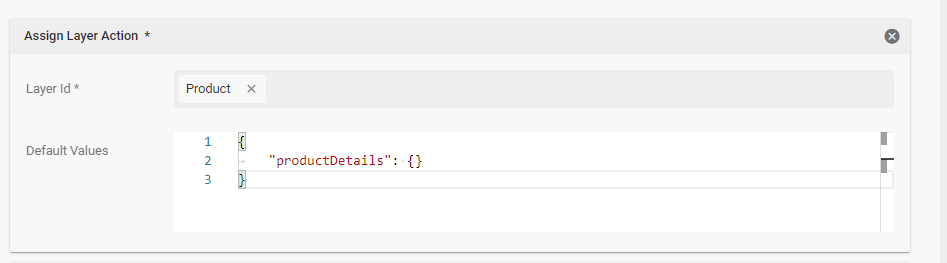
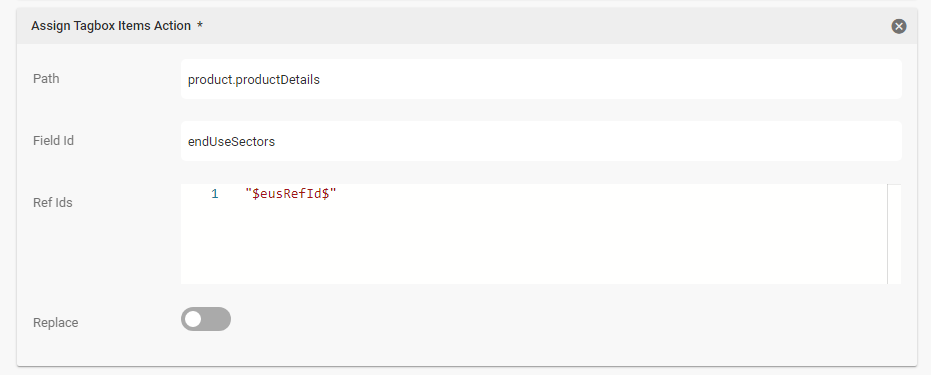
Now assign the Layer “Product” and initiate the single fieldset (aka “press add” to add a new fieldset entry). Then assign the industry tag to the tagbox “industry” in the fieldset.
Don’t use Assign Value Action for tagboxes, as this may result in a metadata validation error when the tag id cannot be assigned. Technical: assign value action will try to assign [null] to the tagbox which invalidates the metadata, which results in metadata errors along the way.
Initiate the fieldset
Assign the tag to the tagbox in the fieldset
"actions": [
{
"kind": "AssignLayerAction",
"layerId": "Product",
"defaultValues": {
"productDetails": {}
},
"traceRefId": null
},
{
"kind": "AssignTagboxItemsAction",
"path": "product.productDetails",
"fieldId": "endUseSectors",
"refIds": "$eusRefId$",
"replace": false,
"traceRefId": null
}
],